ការចំណាយពេលរាប់ម៉ោងអង្គុយស្តាប់ឯកសារសំឡេងប្រជុំត្រឡប់ចុះត្រឡប់ឡើង ដើម្បីវាយអត្ថបទសង្ខេបជារបាយការណ៍ តែងតែជាបញ្ហាដ៏គួរឱ្យធុញទ្រាន់សម្រាប់អ្នកធ្វើការ។ ប៉ុន្តែបញ្ហានេះត្រូវបានដោះស្រាយទាំងស្រុងដោយកម្មវិធីបញ្ញាសិប្បនិម្មិត (AI) ថ្មីមួយរបស់កម្ពុជាឈ្មោះថា "SMEAN-ស្មៀន" ដែលកំពុងក្លាយជាជំនួយការដ៏មានអានុភាពក្នុងការបំប្លែងសំឡេងនិយាយជាភាសាខ្មែរទៅជាអក្សរយ៉ាងរលូន។
នៅក្នុងកិច្ចសម្ភាសន៍ជាមួយក្រុមការងារ Technology Cambodia តំណាងក្រុមស្ថាបនិកបានរៀបរាប់យ៉ាងក្បោះក្បាយពីដំណើរដើមទងនៃគម្រោងមួយនេះ ដែលវាជាស្នាដៃកើតចេញពីគំនិតច្នៃប្រឌិតផ្ទាល់របស់យុវជនខ្មែរ។ យុវជនដែលមានទេពកោសល្យទាំង ៥រូបនោះរួមមាន លោក សាន សិទ្ធិសក្តិ, កញ្ញា អ៊ុន ស្រីពេជ្រ, លោក ផៃ សុមេធ, កញ្ញា ស៊ាន សុផលធានី និងលោក ឡេង គឹមទ្រី ដែលពួកគេសុទ្ធសឹងតែជានិស្សិតបញ្ចប់ការសិក្សាមកពីគ្រឹះស្ថានឧត្តមសិក្សាចំនួនបួនគឺ CADT, AUPP, ITC និង RUPP។។
គម្រោងនេះបានលេចជារូបរាងឡើងតាំងពីឆ្នាំ២០២៥ តាមរយៈកម្មវិធី Techpreneur ដែលរៀបចំដោយ Dichi Academy និង Elix, សហការដោយ MPTC និង CBRD Fund ព្រមជាមួយ USAID រហូតអាចដណ្តើមបានជ័យលាភីលេខ១ ពីកម្មវិធី Turing Hackathon ដែលរៀបចំឡើងដោយ Techo Startup Center និងជាប់ចំណាត់ថ្នាក់ Top 3 ពីកម្មវិធីប្រកួតប្រជែងរបស់ក្រុមហ៊ុន Smart Axiata ហៅថា ACTSmart Incubation Program MSMEs ថែមទៀតផង។ គោលបំណងធំបំផុតដែលពួកគេសម្រេចចិត្តដាក់ឈ្មោះកម្មវិធីនេះថា "SMEAN-ស្មៀន" គឺដោយសារពួកគេមានចក្ខុវិស័យចង់បង្កើតប្រព័ន្ធ AI មួយដែលមានតួនាទីជួយសរសេរឯកសារ និងរបាយការណ៍ជូនប្រជាជនកម្ពុជា ដូចទៅនឹងតួនាទីដ៏សំខាន់របស់ស្មៀននៅតាមឃុំសង្កាត់ដូច្នោះដែរ។
ទោះជាយ៉ាងណាក៏ដោយ ការអភិវឌ្ឍប្រព័ន្ធ AI សម្រាប់ភាសាខ្មែរ មិនមែនជារឿងងាយស្រួលឡើយ ហើយនេះគឺជាបញ្ហាប្រឈមដ៏ធំបំផុតដែលក្រុមការងារបានតស៊ូជម្នះ។ យោងតាមការបញ្ជាក់ពីតំណាងក្រុម ភាសាខ្មែរត្រូវបានចាត់ទុកជាភាសាដែលខ្វះខាតទិន្នន័យ (Low Resource Language) ដែលជាហេតុធ្វើឱ្យក្រុមហ៊ុនធំៗពិបាកក្នុងការបង្កើតផលិតផលសម្រាប់ទីផ្សារមួយនេះ។ បញ្ហាកង្វះទិន្នន័យនេះ តម្រូវឱ្យពួកគេត្រូវចំណាយពេលប្រមូលទិន្នន័យដោយខ្លួនឯង បូករួមនឹងការទាញយកទិន្នន័យបើកទូលាយ (Open Source Data) នានា។ លើសពីនេះ ការចំណាយទុនវិនិយោគដើម្បីបង្ហាត់ម៉ូដែល (Train Model) និងការរក្សាទុកទិន្នន័យ (Hosting Model) គឺមានតម្លៃខ្ពស់។ ប៉ុន្តែពួកគេបានជំនះឧបសគ្គនេះដោយយកប្រាក់រង្វាន់ដែលធ្លាប់ឈ្នះពីការប្រកួតនានា ទៅវិនិយោគលើប្រព័ន្ធ Cloud ធំៗដូចជា Google Colab, DigitalOcean និង AWS ដើម្បីបង្ហាត់ AI មួយនេះឱ្យកាន់តែឆ្លាតវៃ។
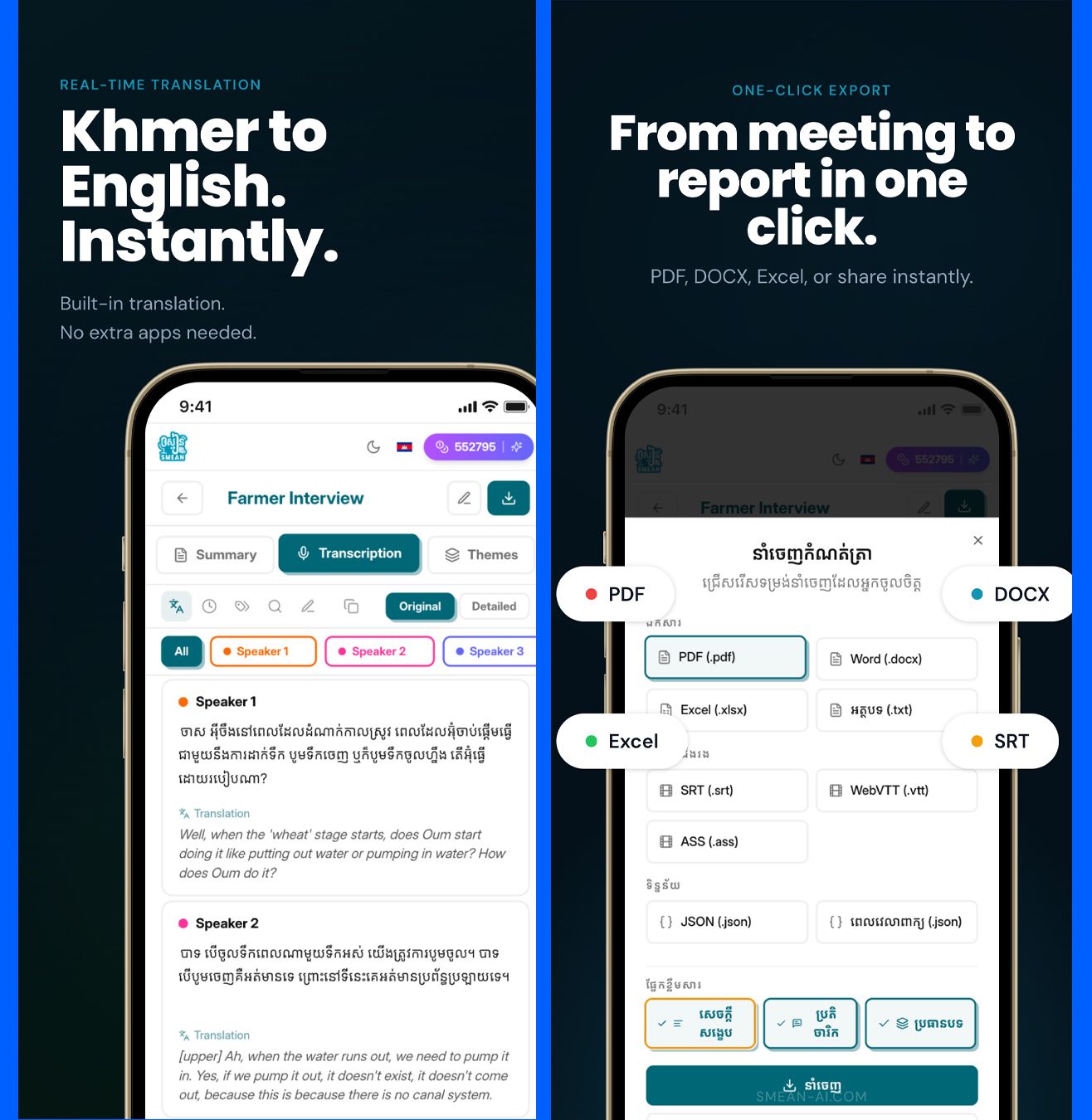
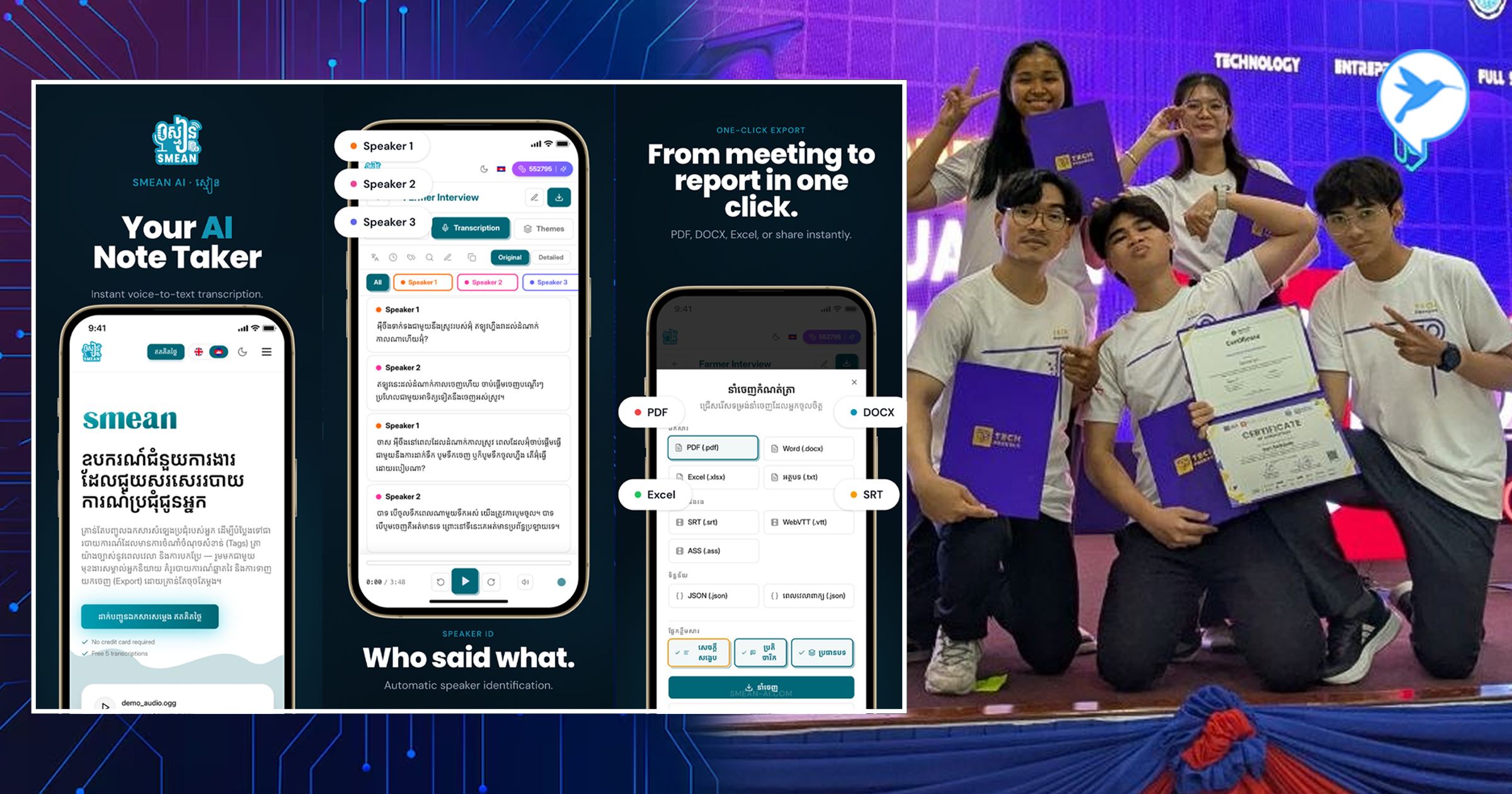
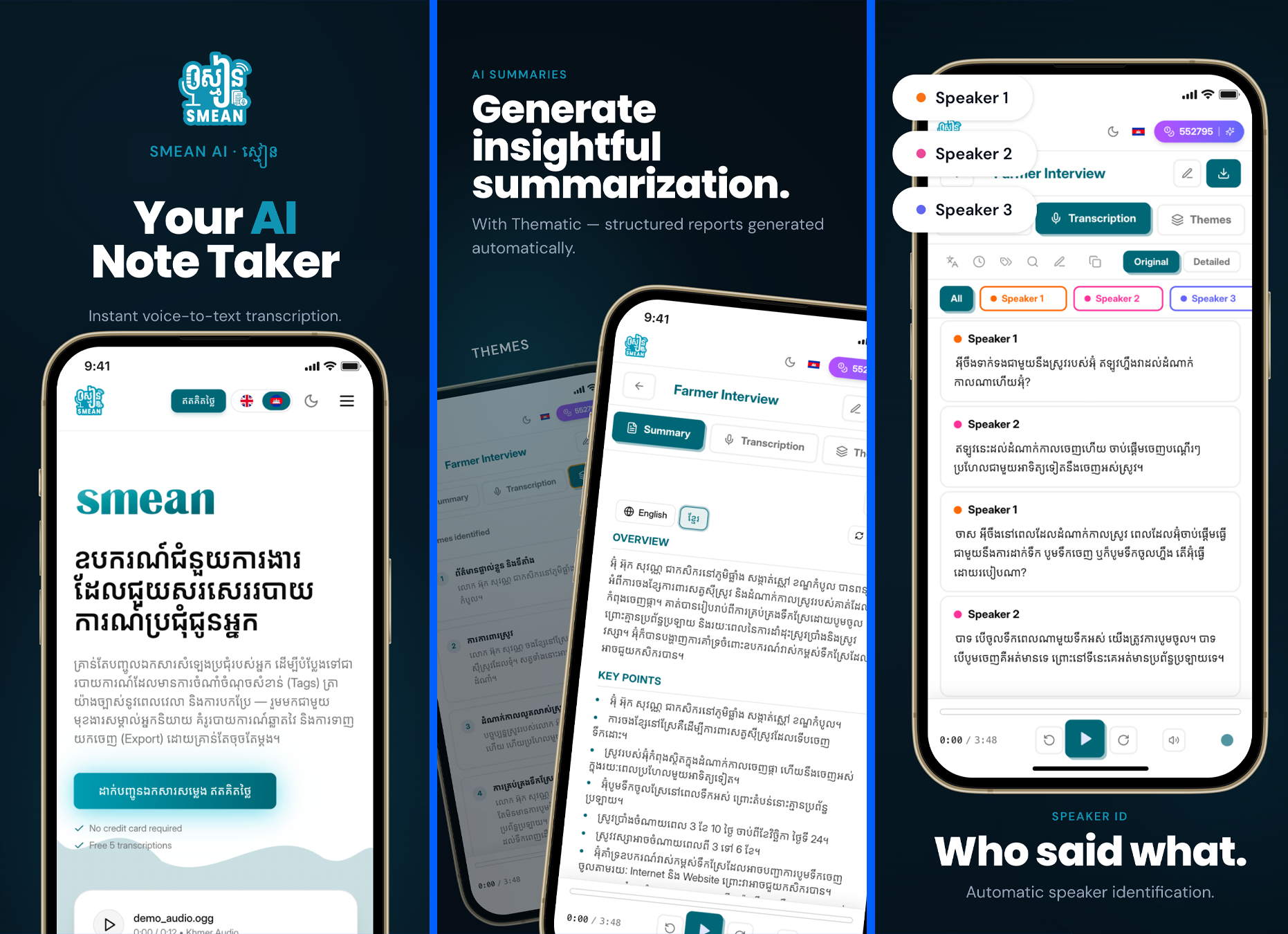
លទ្ធផលនៃការពុះពារនេះ ធ្វើឱ្យ SMEAN-ស្មៀន ទទួលបានការគាំទ្រយ៉ាងខ្លាំងពីសំណាក់មន្ត្រីធ្វើការក្នុងស្ដាប័នរដ្ឋ និងអ្នកជំនាញ ដោយមានអ្នកប្រើប្រាស់សកម្មជាង ១ម៉ឺននាក់។ មុខងារស្នូលរបស់ស្មៀន គឺសមត្ថភាពប្រែក្លាយសំឡេងប្រជុំទៅជារបាយការណ៍ផ្លូវការ ដោយប្រព័ន្ធអាចកំណត់អត្តសញ្ញាណអ្នកនិយាយ ពេលវេលាច្បាស់លាស់ វិភាគទាញយកប្រធានបទសំខាន់ៗ សង្ខេបខ្លឹមសារ និងបកប្រែទៅជាភាសាអង់គ្លេសមុននឹងអនុញ្ញាតឱ្យទាញយកជាឯកសារ Word ឬ PDF។ អ្វីដែលរឹតតែពិសេស ស្មៀនមានសមត្ថភាពខ្ពស់ក្នុងការចាប់យកការនិយាយលាយភាសាខ្មែរ-អង់គ្លេស (Code Switch) បានយ៉ាងរលូន។ វាមិនត្រឹមតែចាប់ពាក្យមួយទល់នឹងមួយនោះទេ តែវាជួយកែសម្រួលពាក្យសម្តីដែលនិយាយរអាក់រអួល ឱ្យទៅជាទម្រង់អត្ថបទដែលងាយស្រួលអានតែម្តង។ បន្ថែមពីនេះ ស្មៀនក៏មាន @smean_ai_bot សម្រាប់អ្នកចង់បញ្ជូនសំឡេងដោយផ្ទាល់ និងមានមុខងារ Subtitle Generator សម្រាប់ជួយបង្កើតអក្សររត់តាមវីដេអូផងដែរ។

ដោយសារអ្នកប្រើប្រាស់ភាគច្រើនជាស្ថាប័នរដ្ឋ និងអ្នកមានការប្រជុំច្រើនក្នុងមួយថ្ងៃៗ ការការពារទិន្នន័យសម្ងាត់គឺជាកត្តាអាទិភាព ដែលទាមទារឱ្យស្មៀនបំពាក់នូវគោលការណ៍ "Zero Retention Policy" ។ គោលការណ៍នេះអនុញ្ញាតឱ្យប្រព័ន្ធលុបទិន្នន័យចោលដោយស្វ័យប្រវត្តិទាំងសំឡេងដើម និងអត្ថបទលទ្ធផល ភ្លាមៗក្រោយពេលដំណើរការចប់ រួមទាំងមានការបម្លែងកូដទិន្នន័យ (Data Encrypt) នៅលើ Database ផងដែរ។ លើសពីនេះ អ្នកប្រើប្រាស់មានសិទ្ធិពេញលេញក្នុងការជ្រើសរើសថា គួរអនុញ្ញាតឱ្យស្មៀនយកទិន្នន័យរបស់ខ្លួនទៅបង្ហាត់ម៉ូដែលបន្ត ឬក៏បិទសិទ្ធិមិនឱ្យយកទៅប្រើប្រាស់ ។

ចំពោះតម្លៃសេវាកម្ម ក្រុមការងារយល់ឃើញថាអ្នកជំនាញភាគច្រើនមានកាលវិភាគប្រជុំមិនទៀងទាត់ ដូច្នេះស្មៀនមិនតម្រូវឱ្យមានការបង់ប្រាក់ជាប្រចាំខែនោះទេ ពោលគឺអនុវត្តការទិញក្រេឌីតតាមតម្រូវការ (Pay-as-you-go) ដែលមានកញ្ចប់តម្លៃសមរម្យសម្រាប់ជ្រើសរើស ដូចជាកញ្ចប់ ៥ដុល្លារ និង ១០ដុល្លារ ជាដើម។ ទោះបីជាថ្ងៃអនាគតក្រុមហ៊ុនបច្ចេកវិទ្យាយក្សដូចជា Google ឬ ChatGPT អាចនឹងចូលមកក្នុងទីផ្សារនេះក្តី ក៏ក្រុមយុវជនទាំង ៥រូបនេះនៅតែមានមោទនភាព និងជំនឿចិត្តខ្ពស់ក្នុងការបន្តអភិវឌ្ឍស្មៀនជា "Khmer-First Tool" ដើម្បីជួយសម្រួលការងារប្រជាជនកម្ពុជាមុនគេជានិច្ច និងកំពុងត្រៀមបញ្ចេញកម្មវិធីទូរស័ព្ទ (Mobile App) ក្នុងពេលឆាប់ៗខាងមុខនេះ។
សាកល្បងប្រើទាំងអស់គ្នា ចុចលីង https://www.smean-ai.com/
អត្ថបទដោយ៖ ផែន ផាន់ណា